|
Pattern |
Mainline
|
|
Aliases |
Main Trunk, Main Anchor Line, Home Line, Ground Line
|
|
Context |
During the development and maintenance cycles, multiple codelines
are created for various reasons. Typical codelines are release-lines
and maintenance-lines and integration-lines. This is particularly
true when using
Codeline per Release,
Parallel Maintenance/Development Lines,
and
Overlapping Release Lines (or
any of their variants). As time goes on, codelines continue to cascade
off of other codelines making the project version tree become wider and
wider.
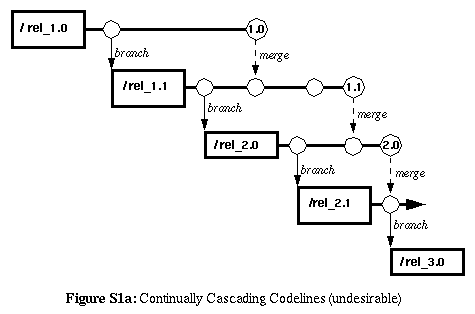
|
|
Problem |
How do you keep the number of currently active codelines to a
manageable set, and avoid growing the project's version tree too wide,
and too dense?
|
|
Forces |
-
Every codeline that is created typically requires a merge back to its
parent branch at some point in time. So more codelines means more
merging, and more merging means more synchronization effort.
-
It seems only natural to branch each new release-line off of the codeline
for its immediately preceding release.
|
|
Solution |
Rather than continually cascading branches upon branches creating an
extremely wide and unwieldy version branch-tree (requiring an enormous
amount of synchronization between each parent-child branch pair), keep
a "home branch" or codeline at the trunk (or right next to the trunk)
of the branch tree.
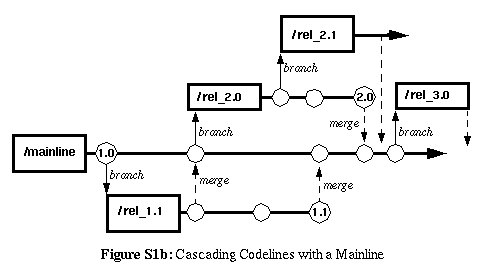
When the time comes to create a codeline for a new major release,
instead of branching the new release-line off of the previous
release-line, merge the previous release-line back to the mainline
branch and branch off the new release-line from there.
The process of merging back to mainline for a particular codeline or
branch is sometimes referred to as
"mainlining,"
"trunking,"
"homing,"
"anchoring,"
or "grounding."
|
|
Variants |
|
|
S1.1 |
Keep a stable, reliable main development trunk that is used used
solely for importing (receiving) stable bases from other codelines. No
development work ever takes place directly on this codeline, and all
integrated changes must come from some other codeline (not a single
discrete activity branch). The only exception to this rule is that
integration changes may be performed for ensuring that the codeline
builds and functions consistently.
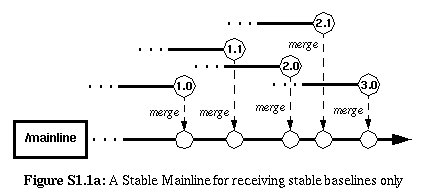
|
|
S1.2 |
Use the trunk as the latest-and-greatest (LAG) development line which
evolves forever and to which all codelines for previous releases are
eventually merged after they have been "retired." The trunk gets used
as the development line for the next/latest development release (not
maintenance, but development, as in significant enhancements and new
features). Thus, when work for release B2 is ready to begin and work
for release A1 is completed or is tapering off, then a new branch
is spawned to finish up the A1 effort (see Deferred Branching)
and the LAG-Line is used for work toward release B2 (which is the new
"latest and greatest" development effort).
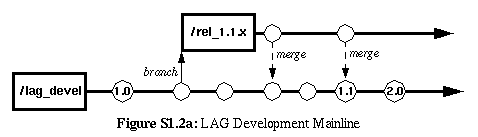
The process of doing merging for a particular codeline or branch to the
LAG-development line is sometimes referred to as
"LAGging,"
"mainlining,"
"LAG-lining,"
or "mainstreaming."
Although often used as a Mainline, a LAG-Line may also be used
in conjunction with a Stable Receiving-Line as the mainline:
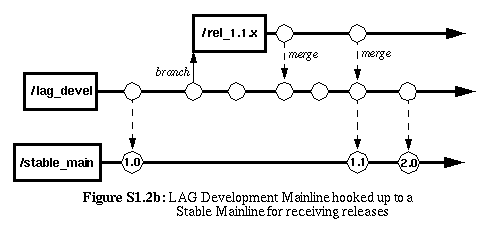
|
|
S1.3 |
A mainline need not be restricted to being only the topmost (root)
branch in the version tree, and it certainly need not be
the union of all its subbranches (sometimes such a "union" would result
in a meaningless configuration). Rather, a mainline is simply a high-level
codeline for which everything underneath it can be integrated into a
working system, and which represents a logically coherent convergence
of team effort. It requires much additional of integration effort and
formality (often overkill for small shops and small projects), but
larger shops and larger projects commonly grow into the need for multiple
mainlines. And some of those mainlines may even feed back up into
others: a mainline for a subsystem or release may feed into an
integration-line which leads back up to a system-level mainline.
One obvious use for multiple mainlines is when you have codelines
representing persistent variants that simply cannot be combined
together. For example, a multi-platform project with multiple
platform lines
may require the use of a mainline for each major platform.
Similarly, it may be appropriate to use a mainline for each major
project branch in a set of
multi-project lines.
More common however is to see multiple mainlines used in conjunction with
staged integration lines.
A set of staged lines is often used for each major release, and/or for
each major subsystem or component of a project. When staged-lines are
used in conjunction with
codeline per major release, and/or with one or more
component lines, the topmost promotion branch often serves double-duty
as a mainline that is specific to the given release or component.
|
Resulting
Context |
-
Reduces merging and synchronization effort by requiring fewer
transitive change propagations.
-
Keeps full revision names to a manageable length (both conceptually, and
physically - so as not to approach the maximum limits of the length of
the command-line).
-
Provides closure (closing the loop) by bringing changes back to
the overall workstream instead of leaving them splintered and
fragmented.
|
Related
Patterns |
Mainlines often need the strongest codeline policies and owners
of all codelines. They will typically have either very restricted
access (if used as a Stable Receiving Line) or else very
relaxed access (if used as a LAG development).
If used as a LAG development line with deferred branching,
the mainline may serve as the parent in a set
of Parallel Maintenance/Development Lines and/or
Overlapping Release Lines. If used as a stable receiving line with
early branching then typically one uses codeline per
release when branching off the mainline (although a LAG mainline
branching off a stable mainline is also somewhat common).
Also, the last promotion-level in a set of
Staged Integration Lines
often serves double duty as a stable mainline.
|
|
Pattern |
Parallel Maintenance/Development Lines
|
|
Aliases |
Parallel Fix/Feature Lines
|
|
Context |
You've finished a release of a version of the project and need to start,
or continue development on the next major release.
|
|
Problem |
How do you conduct development of the next major release while at
the same time responding in a timely manner to all the many
bug reports and enhancement requests that are inevitably going
to be logged against the current release?
|
|
Forces |
-
You need to make steady progress toward implementing the new
functionality slated for the next major release.
-
You need to respond quickly to bugs and enhancements logged
against the current release.
-
Critical bug-fixes and enhancements need to be effected immediately,
often well before the next major release is ready to ship.
-
Maintenance effort (bug-fixes and enhancements) in the current release may
be incompatible with some of the functionality or refactoring already
implemented in the next release.
|
|
Solution |
Rather than trying to accommodate maintenance of the current release
and development of the next release in the same codeline, split
maintenance and development off into separate codelines. All bug-fixes
and enhancements to the current release take place in the maintenance
line, effort for the next major release takes place in the development
line. Ensure that changes in the maintenance line are propagated to
the corresponding development line in a regular fashion
(see Merge Early and Often,
and Change Propagation Queues).
One way of doing this is to create two new branches: one for maintenance
and one for development.
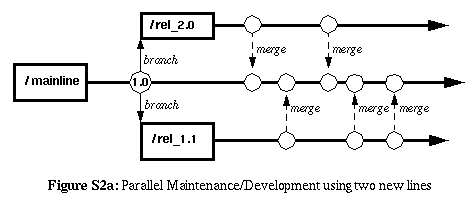
The more common approach is to create one new branch. If the new branch
that is created is used for development, then maintenance work happens
on the same codeline is initial development for its corresponding
release. So the branch "invariant" is the major release functionality.
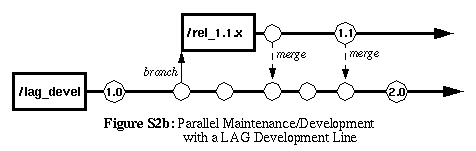
Another approach uses Deferred Branching and LAG
Development Line by keeping the development on the same codeline
and branching off to create the maintenance-line (so the branch
invariant is "maintenance" effort versus "new development" effort).
|
|
Variants |
|
|
S2.1 |
With this approach, instead of branching off immediately after
release, you branch off before the release. This allows
you to branch instead of freeze! Instead of freezing the
codeline during release engineering activities, a separate line is
created for release integration and engineering while allowing other
development to continue taking place on the development line (which
is why it is sometimes called an anti-freeze line). Upon
successful release, the release-engineering line becomes a
release-maintenance line. It still serves the same purpose of
"sync and stabilize" but now it is an ongoing effort that continues
even after the release.
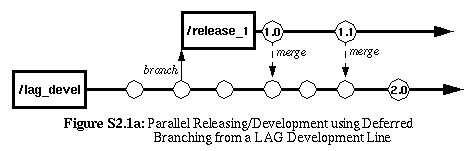
|
Resulting
Context |
Changes can take place in each of the two codelines at the appropriate pace.
Critical fixes and enhancements can be implemented and delivered without
immediately impeding future development. Maintenance
releases or "patches" can be periodically released without severely
impacting development on the next release. The
Codeline Owner of the development line can set a policy for how
and when changes are propagated from the maintenance line to the development.
|
Related
Patterns |
Merge Early and Often,
and Propagate Early and Often<
should be used to ensure that fixes and enhancements effected in the
maintenance line are eventually migrated to the development-line (so
the same problems don't reappear in a later release).
Change Propagation Queues
may be used to ensure that changes are propagated in the correct order.
This pattern can be viewed as one particular realization of a
Policy Branch. The fact is different
policies are needed for the maintenance of the old line and development
of the new line. Changes on the old line need to be turned around very
quickly and should be minimal in their scope. Changes in the development
line typically have broader architectural implication, impacting more of
the project at once and requiring effort for design, implementation, and
testing. The integration "rhythms" for the two codelines are thus
drastically different (the maintenance line needs to "salsa" while the
development line needs to "waltz").
|
|
Pattern |
Overlapping Release Lines
|
|
Aliases |
Parallel Feature-Lines, Incremental/Evolutionary Delivery Lines
|
|
Context |
You need to develop functionality for two major incremental releases
of the software within a short timespan of each other. The schedule
for delivering each increment is fairly aggressive (as it always is).
|
|
Problem |
How do you make progress on both development increments without
having either one severely impact the other?
|
|
Forces |
-
Cycle Time.
It would be nice to avoid any unnecessary waiting or delays for
work on the next release.
-
Stability.
When performing release integration and engineering for the current
release, it is vital that the configuration for the release is
reliably correct and consistent. Development and maintenance
activities on the codeline could easily compromise the integrity
of such a "codeline in waiting."
|
|
Solution |
Branch off the current development increment's codeline and start
a new codeline for the next development increment. Development on
the two codelines progresses concurrently on separate streams
of development. From time to time, features and changes in the
codeline for the earlier release will need to migrate to the
codeline for later release. Propagate these changes early and often
at appropriate stable baselevels.
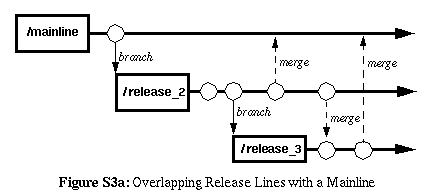
When creating a separate codeline for each release cycle, often, the
release codeline will be created as soon as effort begins for the new
release. However, if you don't require isolation of the entire effort,
Deferred Branching may be employed to create the release-line
only its development needs to occur in parallel with that of subsequent
releases.
|
Resulting
Context |
Changes can proceed in parallel on the two codelines while in isolation
from one another. The current development increment does not need to be
slowed down by efforts toward a later incremental release. However,
there is a now a dependency of the later release-line upon changes and
fixes in the earlier release-line. These integration efforts for these
propagated changes is a necessary trade-off over freezing all efforts
for release-line while it waits for completion of the other.
|
Related
Patterns |
As with
Parallel Maintenance/Development Lines,
Merge Early and Often,
and Propagate Early and Often
should be used to ensure that changes in the codeline of the earlier
development increment are eventually migrated to the subsequent
development increment.
Change Propagation Queues
may be used to ensure that changes are propagated in the correct order.
This pattern is also a particular realization of a
Policy Branch.
The two development increments have different long and short term goals
and require a different tempo for their development and integration
efforts.
|
|
Pattern |
Docking Line
|
|
Aliases |
Holding Line, Staging Line, Lay-Away Line, Shared Integration Line
|
|
Context |
The context is similar to that of
MYOC (Merge Your Own Changes).
A developer has finished a change-task and is ready
to merge it back into the codeline. However, in this case the nature of
the codeline requires a very paranoid codeline-owner
(Codeline Ownership)
This is usually because the codeline in question is associated with
sufficiently high-risk or high-complexity development, or because it
demands a greater degree of reliability and consistency than other
codelines. Whichever the case, the consistency and integrity of the
codeline is relied upon by important people and important tasks, even
more than usual.
|
|
Problem |
Who should perform the merge, and who assumes the burden of
ensuring it is integrated correctly?
|
|
Forces |
-
As with MYOC, we have the case of dueling
ownerships: the change-owner versus the code-owner versus the
codeline-owner.
-
MYOC also tells us that follow through
needed to avoid social disconnection (throwing it over the wall), and
impact ignorance (lack of awareness of the downstream effects of one's
changes). This suggests the change-owner or code-owner should perform
the merge.
-
The high-risk and/or high-reliability nature of this particular codeline
suggests it really must be the codeline owner who performs the
merge to ensure and preserve the integrity of the codeline (because many
critical tasks depend upon it).
All the other forces mentioned in MYOC still apply.
|
|
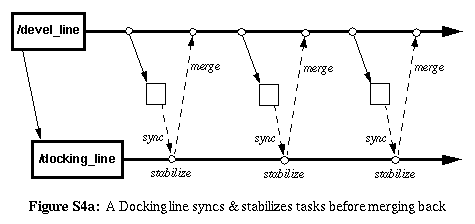
Solution |
Add another level of indirection by adding another line of integration
to balance the tension between ownership, follow-through, and reliability.
The integration-line is a persistent branch off from the development-line
which serves as a "docking area" for changes that need to be integrated
back into the original codeline. The change-owner merges (pushes) the
changes to the docking-line, integrating with all the predecessor
changes. The codeline-owner imports (pulls) one or more changes at a
time from the docking-line and integrates them back into the
original codeline.
|
Resulting
Context |
The new integration-line is a "mediator" of sorts between the various
owners. The change-owner or code-owner still gets to follow-through by
merging their changes to the docking line and having to understand and
resolve any conflicts it may have with previous change-tasks. The
codeline-owner still gets to ensure the reliability and integrity of
the codeline by "syncing" the docking-line with the original codeline
and having complete control and authority over its consistency.
The cost of meeting the various owner's competing needs of
follow-through and reliability is the added integration effort.
However, most of the merging difficulty is handled during the merge to
the docking-line, by the person most familiar with the code that was
changed. The codeline owner primarily verifies the reliability of the
state of the docking line and then merges it back to the original
codeline. Since that is where the changes originated, and no other
development should be taking place on the original codeline, most of
these merges should be trivial because there are no concurrent changes
between the docking-line and the original codeline.
If the merged changes in the docking line fail the codeline owner's
codeline consistency and integrity checks, then the codeline owner
works with the change-owner or code-owner to resolve the issue; but
this should be the exception rather than the rule. In the meantime,
the person merging the changes to the docking-line avoids having to wait
for verification of their merge-efforts before continuing on to another
development task. Since the docking-line is separate from the codeline,
their work has been effectively isolated, which allows them to return
to other important tasks.
|
Related
Patterns |
Merge Early and Often should
be used to merge changes from the original codeline into the docking-line.
Ideally, this is also the case when merging from the docking-line back
to the codeline. But if the codeline is high volume or high-load then
it may be infeasible to merge change-task at a time. In this case
use Multi-Merge Early and Often,
allowing the docking-line to accumulate a handful of changes before
merging it back to the original codeline.
A situation to that of Docking-Line might arise if the
change-task owner is different from the code-owner of the modified
files. This might result in the need for another docking-line
(the fewer the better), in which case you have now graduated from a
single docking-line to
Staged Integration lines.
Otherwise you may use only one docking-line and resolve who merges to
it (the change-owner or the code-owner). In this case,
MYOC
applies and you can treat the code-owner as the codeline-owner
for a Component Line.
|
|
Pattern |
Staged Integration Lines
|
|
Aliases |
Promotion Branches, Promotion Lines, Cascading Integration Lines
|
|
Context |
Development tasks and software changes are frequently required to
progress through defined, discrete stages of maturity: Changes
are proposed, then analyzed and performed; then perhaps they
are promoted through levels of review, debug, unit-test, integration
test, and system test.
Other times changes may need to progress through multiple levels of
ownership, responsibility, and accountability: Changes might first
be effected to a particular file or module, then integrated
and tested at the component-level, then the subsystem-level,
then the site-level, then the product or system-level.
In either case, there is often the need (or contractual obligation)
to provide strict traceability and auditing of changes as they
are promoted through these stages of their lifecycle,
|
|
Problem |
How do you use the facilities of your VC tool to track and control
changes through defined levels of promotion?
|
|
Forces |
-
Some promotion levels may correspond to the completion of certain events:
review, unit-test, system-test, etc.
-
Other levels may correspond to states of quality assurance and control
to represent some degree of reliability and security.
-
Still other levels may correspond to assignment of ownership, responsibility,
accountability, and scope (e.g module, component, product).
-
Not all of these kinds of promotion levels are well suited to the same
set of mechanisms provided by your VC tools.
-
Among the various promotion levels, some will implicitly require
integration to verify/validate correctness, consistency, or to ensure
appropriate transferral of responsibility.
|
|
Solution |
Some VC tools and SCM systems already support a notion of promotion
levels for tracking and control. If your tool is one of them,
then look closely at the documentation to ensure the supported
promotion-model is a good match for the model you need to implement.
Look at any built-in access controls and transition rules, and
how the promotion levels themselves are defined, ordered,
and represented. Are they represented as attributes, branches,
labels, or something else? How well does that meet your needs?
Otherwise, if the set of promotion levels needed consists predominantly
of integration points and the transfer of responsibilities between roles,
then use a separate integration-line for each promotion level in the
hierarchy.
When original changes are made, they are considered to be at level '0'
(often corresponding to a development line or activity-branch). When
the change is completed, it is then propagated (merged) to the first
promotion-line in the hierarchy. After it is successfully integrated and
verified there, then it is propagated to the next promotion-line, and so
forth until it proceeds through the final promotion level. The last line
in the chain might be a Stable Receiving-Line, or it might be
development line (like a Docking Line split across into multiple
lines, but which eventually feeds back to the primary development line).
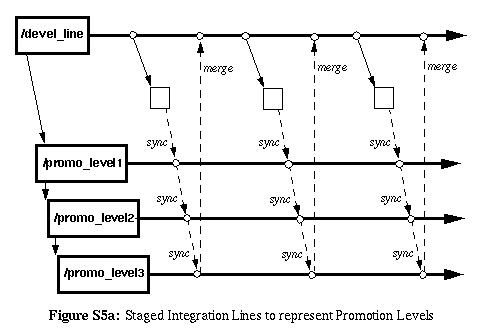
The promotion-level associated with a given revision may be determined
by identifying which promotion branch it belongs to. The progression
between levels may be traced by using the VC tool to produce a report
of the ancestry of the particular revision (a feature commonly provided
by VC tools).
The promotion level of an entire change-package (a logically
related group of revisions that were modified and submitted together)
is harder to determine: Identify the revisions in the change-package and
find their branches. They should all be on the same branch (if they
aren't, you have detected a consistency error in execution of the
change-control process). Then look at the descendents of each revision
to ensure the progress through the promotion branches together,
and in the proper order. If your VC tool doesn't do this for you
in 1-2 simple steps, create a script or macro that does this using
the tool's querying and reporting capabilities.
|
|
Variants |
A common point of variance in implementations involves which codeline
is the one into which development changes are initially merged. It
usually depends on the size and formality of the development group.
|
|
S5.1 |
In some cases elements are checked-out from the highest-stage (most
stable or must trusted) and checked-in to the lowest stage. The changes
then propagate through the integration stages to the highest stage,
where they are finally ready to be integrated back into the development
codeline and may once again be seen and used by the developers using
that codeline.
This is the model depicted in the figure above and is sometimes
characterized using the phrase "What goes up, must come down."
It is commonly used by larger and more formal or conservative groups
that insist on having the most stable/trusted versions for making
development changes: checkouts happen at the most stable stage, the
development line, and then have to propagate back up to it from the
lower levels. You work only with "trusted" elements, and any changes
have to go back through the ranks to "re-earn" your trust.
|
|
S5.2 |
In other cases, elements are checked into and out from the
lowest-stage branch, and then the changes propagate through to the
higher-level promotion branches. The developers are then always working
with the most recent changes, while the higher-level integration
branches are used to successively stabilize changes as they propagate
up to the highest-stage integration line. At each stage of integration,
the team members working on that codeline are responsible for ensuring
the necessary degree of consistency/volatility for their own needs, and
then the changes propagate through the ranks as each group requires
more consistency and less volatility for the type of work they are
performing.
This promotion scheme is sometimes characterized as "the Stairway to
Heaven." It is frequently used by smaller and more informal groups that
still desire the added stability that comes from filtering changes through
multiple stages of integration (used primarily for progressive verification
of changes before release). But at the same time the developers don't need
to wait for changes to progress through the entire promotion cycle before
building upon those changes. It is a riskier, more streamlined approach
that trades off some degree of safety for productivity.
Part of this risk is mitigated by the fact that less integration effort
is typically needed for a given change-task: it is likely to be more
"in sync" with the development line because it didn't have to wait for
changes to progress through the promotion cycle before it could build
upon them. At the same time, if something does go wrong when merging
back to the codeline, it may be harder to disentangle the result as it
progresses through the subsequent integration lines.
|
Resulting
Context |
-
Promotion levels for revisions and change-packages can be readily
identified and traced.
-
The staged promotion branches function like a progression of gates,
or a sieve, for transferring and filtering the responsibility
and reliability/stability of changes as they progress through the
promotion levels.
-
Branches are well suited for promotion levels that represent transfer
of ownership, responsibility, and accountability. When a change
is merged from one branch to the next, the revisions on the new branch
are now the responsibility of its codeline-owner.
-
Branches also work well for promotion levels that inherently correspond
to integration points in the lifecycle. Merging the change from
branch to branch performs the necessary integration. However, the
merge overhead can be effectively minimized by using Virtual
Codelines as the promotion branches.
-
Promotion branches can be overkill for smaller shops performing only
"loosely serialized" development rather than full-scale parallel
development. Such shops typically don't have too many parallel
development tasks going on at the same time (just small pockets
of parallelism here and there).
Rather than imposing numerous additional levels of integration, the
project might be better served using a
Deferred Branching
approach with a
Mainline
(and possibly a
Docking Line).
If promotion levels are still needed, they can be represented using
labels or attributes on element versions.
-
Branches are less than ideal for promotion levels that correspond to
static states of quality, maturity, or reliability. Labels and
attributes are better suited for this purpose. Branches are
inherently dynamic and evolving entities, whereas these kinds of
promotion states represent frozen points in time, or static levels
of "goodness."
-
Another problem with using branches for static "goodness" states:
Oft times there will be errors where a change or revision is improperly
promoted, or was properly promoted, but later turned out to be
flawed. Backing-out revisions from a branch is substantially more effort
and more complexity than removing a label or attribute corresponding to
the promotion level. Although this is easier to do with a "virtual"
promotion-line, it's still more likely to better accomplished with a
promotion attribute, or label (as opposed to a codeline label trying to
fit two purposes at once).
|
Related
Patterns |
In many respects, this pattern is merely a composite of one or more
patterns that add an extra level of integration: One can regard a
Docking Line as a minimal example of staged integration with two
lines; so can Inside/Outside Lines, and Branch per Task.
One or more Component Lines, Remote Lines,
Subproject Lines, and Stable Receiving Lines
will frequently participate in a set of staged integration lines.
For promotion hierarchies that are about three or more levels deep,
it may be highly desirable to use a Virtual Codeline for
one or more of the promotion lines. This will help reduce the
amount of trivial copy-merging, which can become substantial
after three or more levels of integration!
|
|
Pattern |
Change Propagation Queues
|
|
Aliases |
Change Migration Queues, Change Transfer Queues
|
|
Context |
You have been using
Parallel Maintenance/Development Lines
and/or
Overlapping Release Lines
and you need to propagate changes from one codeline to the other.
|
|
Problem |
How do you propagate changes between sibling codelines in a consistent
fashion and in the proper order?
|
|
Forces |
-
You typically want changes to be integrated as early as is conveniently
possible, but with minimal impact to others working in the codeline.
-
If changes are propagated in a sequence different from the order in
which they were effected in their originating codeline, integration
may become very difficult or confusing, or may result in more
changes than desired being integrated at once (in the case of dependent
changes).
-
It would be nice if changes could just always be propagated immediately
by the person who made them. But this isn't always feasible, depending on
the current state of the work in the receiving codeline, or the mismatch
between integration intervals of the sending and receiving codelines.
|
|
Solution |
When the number of changes being Propagated Early and Often
makes it hard to easily remember the completion order and dependencies
between propagated changes, then implement an incoming change
propagation queue for the codeline. Depending upon the SCM tools
available to you, this might be done a number of different ways.
-
If all changes to be propagated are tracked in a change control system,
create individual change-requests for the propagation of each change.
Record its dependency upon the unpropagated-change and the target
codeline of the propagated change. Now you can determine the order
in which to propagate the changes by looking at the completion times
of the corresponding pre-propagation changes. Program a script or
macro to query the tracking system for a given codeline and report
the propagation order for all pending changes to be propagated.
-
If this is beyond the capabilities or current usage of your tracking
system, see if your VC tool supports change-tasks (sometimes
called change-packages or change-sets). A number of VC
tools do this, or can be easily customized to do this. If yours does,
then see if tracks change-tasks or provides some kind of completion
log to look them up and find out when they occurred, and what their
contents are. If so, you can usually customize this in a manner similar
to the way we customized the tracking system above.
-
You can write a wrapper script (or a "trigger" if your VC tool
provides them for change-package operations) to "submit" revisions in a
change-package against a target codeline. The "submit" script can consult
the codeline policy for the target codeline and see which codelines are
on the export list to receive propagated changes.
Once it does this, the submit script can use a regular file, or even
a database of some kind, to maintain a "propagation queue" for each
codeline. When a change is submitted, an "entry" is placed at the end of
the propagation queue for all codelines in the export list of the codeline
receiving the submitted change. A change may then be propagated into
a codeline if and only if it is at the head of the propagation queue,
or the queue is empty. After it has been propagated, it is removed from
the head of the queue.
Often, the most convenient implementation will be some combination of
the above. A script may be used to integrate change-packages with the
tracking system to automate the creation, modification, and control
of change propagation queues.
|
|
Variants |
|
|
S6.1 |
This goes a step further than the above and usually requires a
home-grown "submit" wrapper or trigger script. When a change is
submitted, the submit script will try to auto-propagate (auto-merge)
the change into the target codelines if their propagation queues are
empty. If the queue is not empty, or the the propagation cannot be
performed automatically without human assistance, then the
propagation-task is appended to the codeline's propagation queue.
If auto-propagation succeeds, then the process continues and determines
if the change can be auto-propagated to the next codeline in the
propagation chain (if there is one), queuing up the change if it can't
be autopropagated.
The relative ease and risk of the auto-propagation attempt depends largely
on the sophistication of the SCM tool's merge facilities. It may let the
propagation proceed if the tool's think the merge is trivial. Or it may
be more sophisticated, providing configuration and dependency information
to let the submit script determine whether or not the receiving codeline
has changes which might conflict with the propagated change, or which
should at least require testing and verification before proceeding.
|
Resulting
Context |
-
Proper ordering of propagated changes can be easily tracked and
enforced.
-
Some propagation tasks may be delayed waiting for a predecessor
task to be propagated. This is deemed acceptable in order to prevent
changes from being propagated in the wrong order and direction.
-
If PYOC is being used, propagation queues
guards against developers accidentally propagating other people's changes
while propagating their own.
-
If the Codeline Owner is
performing all integrations for the receiving codeline, then change
propagation queues can be very helpful to the codeline-owner for
tracking dependencies between submitted changes, even when
Multi-Merging is used
to integrate several change-tasks at once.
-
If you have to roll-your-own solution, rather than making straightforward
customizations to a tracking system or SCM system, then the implementation
and testing effort involved can be quite significant.
-
If you implement the propagation queues yourself using regular files
(rather than a database), you will need to go to the trouble of
using file-locking to prevent concurrent updates to the propagation
queues.
-
You may need to be very familiar with how to write scripts using
your VC and tracking tools. Unless your need for propagation queues is
quintessential, the effort involved may far outweight the benefit of
implementing them from scratch.
|
Related
Patterns |
If propagation queues are used it is almost imperative that it
be done in conjunction with
Merge Early and Often and Propagate Early and Often.
MYOC and PYOC are also recommended, but not MYOC is not
absolutely required.
When using propagation queues, it is of course crucial that the
codeline policy indicate the destination codeline propagated
to from a given codeline, and that the codeline owner is well
aware of these propagatioin relationships. In fact, such propagation
relationships may often be negotiated between codeline owners, where
the owner of a prospective destination codeline requests the owner
of a prospective originating codeline to define the auto-propagation
relationship from the originating codeline to the destination codeline.
It is important to make effective use of a mainline so that
the depth of (transitive) propagations is kept to a minimum.
|
|
Pattern |
Third Party Codeline
|
|
Context |
You are responsible for maintaining and porting source code from a
third party external to your group or organization. It may be that the
code is freeware (e.g. emacs, perl, gcc) or simply that you repackage
the code (perhaps with some value-added features) from another vendor
to customers that use your product/environment. Some of the changes you
make may get cycled back to the vendor but some of them won't be.
Thus, you frequently have to cope with keeping your own custom versions
and/or configuration of the code "in sync" with updated releases from
the vendor. You will also likely need to reproduce earlier versions of
the third-party code.
|
|
Problem |
What is the most effective integration/synchronization strategy to to
accommodate vendor updates with your own custom changes while creating
as few headaches as possible?
|
|
Forces |
-
You want to minimize the manual effort required to incorporate the
latest vendor release with any custom changes you made.
-
You need to be able to reproduce present and previous releases of
your customized version.
-
You need to be able to isolate your changes to the vendors code for
each release (so can send patches to the vendor if necessary, and so
you can retrace what needed to be changed)
|
|
Solution |
Use your version control system (VCS) to archive both the versions of
the software you receive from the vendor, as well as the versions you
deliver to your customer. Use the branching facility of the VCS to
track separate but parallel branches of development for the vendors
code, and your customized versions of the vendors code. When the
vendor code is received, make it the next version in the vendor branch
and then merge the code from that branch into your customized branch.
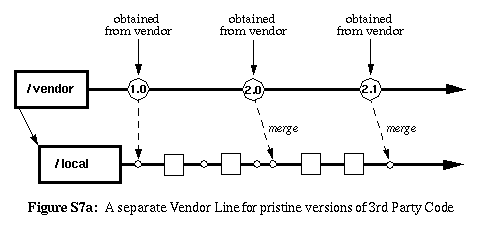
|
Resulting
Context |
-
You can easily reproduce prior versions of your own releases as well
as those of the vendor.
-
Customization differences can easily by isolated and reproduced so
you can see what you had to change for a given release.
-
Differences between vendor releases can easily be isolated and
reproduced to see what the vendor changed from release to release
-
By tracking customization changes on a separate "branch" from
vendor changes, you are basically applying a "divide & conquer"
approach of orthogonalization: instead of one big change, you
logically partition it into vendor changes and custom changes from a
common base version. This reduces merge complexity.
-
The resulting project "version tree" reflects the real-world
development path relationships between the vendor and your group.
-
Requires more storage space than simply keeping one source tree or
one set (branch) of versions of the source tree.
-
Requires the oft-despised merging of parallel changes. There are
many who feel that "merging is evil!" However, in this case, you
are not the one who controls the development of the code. You are at
the mercy of the 3rd party supplier for this. The best you can hope
for is that they incorporate all of your changes into their
code-base. Thus, merging is really unavoidable here.
|
Related
Patterns |
This pattern is really a variant of
Parallel Maintenance/Development Lines.
Here, the maintenance line and the development line are distributed
across two different sites and one of the needs to be "replicated" or
"mirrored" at your site.
A third-party line sometimes participates in a pair of inside/outside
lines or serves as a remote line. If the number of
third party updates and baselines is expected to be significantly more
frequent than the number of in-house updates and baselines, then it may
be prudent to have the third-party be the parent of the corresponding
development line. In this case the third party-line may sometimes serve
as the mainline and/or development line in the pair of Parallel
Maintenance/Development Lines.
|
|
Pattern |
Inside/Outside Lines
|
|
Aliases |
Internal/External Lines, Local/Remote Lines, Central/Remote Lines
|
|
Context |
Your project must allow outsiders to modify source code for maintenance
and/or development. However, those outsiders aren't all at the same
location, or even at a handful of select locations. They may be from all
over the globe and any one of a number of sites. External developers will
centralized access to the codebase via some kind of remote connection.
This is common for open source software development projects with a large
but core group of primary developers (e.g. Perl, Apache, Linux, etc.)
|
|
Problem |
How do you give developers the access they need without permitting
a total stranger to (accidentally or maliciously) completely destroy
the consistency and integrity of the codeline?
|
|
Forces |
-
The codebase must be made accessible to a respectable number of remotely
dispersed people, not all of whom you can afford to implicitly trust.
-
The consistency and integrity of the codeline (as well as the codebase)
must be maintained.
-
Waiting for checkout-locks to be released may be entirely intractable
for respectable numbers of geographically dispersed individuals
collaborating together.
-
Some degree of control must be implemented to safeguard against
potentially destructive operations and individuals.
|
|
Solution |
Use a separate codeline for "internal" use that is restricted only
to trusted individuals at the master development site (the once which
controls and administers the repository). Everyone else uses an "external"
codeline which may restrict certain operations, or simply serve as a
firewall to the internal line. Changes on the external-line are
periodically merged to the internal-line by the latter codeline's owner
(and perhaps by some of the other trusted individuals). All official,
stable baselevels are kept on the internal codeline.
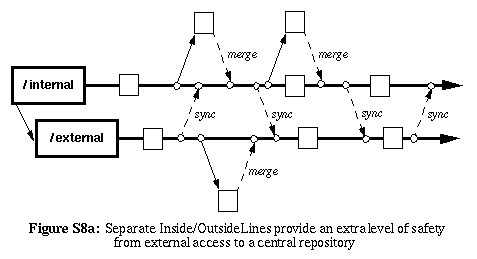
Choosing an appropriate codeline-owner for the inside-line should be
no more difficult than usual. The same is not true for the outside
line since most outsiders don't get to communicate face-to-face
very often. Since the external-line serves as the outside gateway
for the internal-line, select one of the trusted individuals for
the internal-line to serve as the owner of the external-line. This
will help keep the policies for the two codelines in alignment with
each other.
|
Resulting
Context |
-
Developer's on the outside-line have the necessary access to the
repository without having to wait on one another (possibly across
disparate timezones) for checkout-locks to be released.
-
The outside line serves as a "firewall" to protect the inside-line from
unauthorized or unintended changes. Although the outside-line itself
may fall into a state of disrepair, the inside line is insulated from
such disasters.
-
Extra merging is required to propagate changes to the inside-line and
verify their correctness, but this is deemed essential to preserve the
integrity of the primary-line and the safety of the codebase.
|
Related
Patterns |
The use of strong Codeline Ownership and Codeline
Policy is especially important for such a geographically
dispersed group of collaborating developers. The outside-line
will need to be some from of Relaxed-Access Line while
the inside line will obviously need to employ some form of
locking for a Restricted-Access Line.
For an added degree of safety/stability (at the expense of more
integration overhead), add a Stable Receiving Line which is
reserved for the sole purpose of receiving propagations of stable
baselines from the internal line.
This pattern is similar to Remote Line but the external
line isn't for a particular remote-site; it's for all of them!
A remote-line is also better suited for replicated (or "mirrored")
repositories instead of centralized access to a lone repository.
|