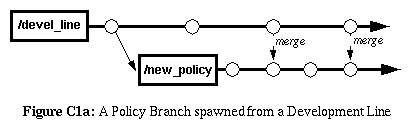
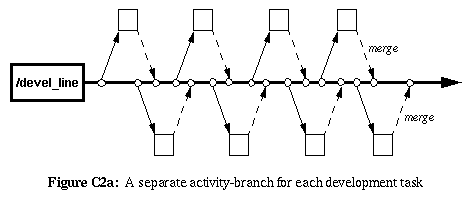
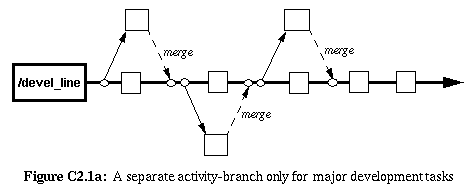
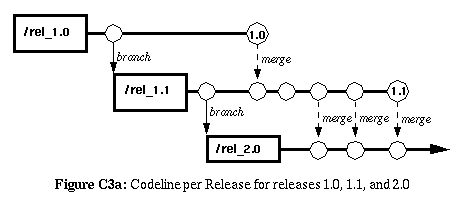
|
Solution |
For a new platform requirement where no multi-platform needs
previously existed, create a new codeline for that platform (a
platform-line). If multiple platforms are needed, then a
new codeline for each platform. All creation and modification of
platform-specific content should take place on the codeline for the given
platform. Files that require no special awareness of differing platform
requirements can remain on the main (common platform) development line.
the platform line should never merge back to the development line while
differences in operating platforms are needed in source code or build
files.
Initially, it may be sufficient to create only a single platform-line
for the first additional platform.
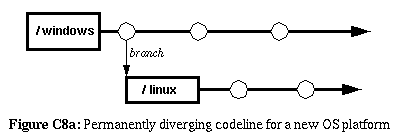
But, if multiple-platforms are being used, you will probably need to
go through the existing codebase and separate out platforms differences
into two or more codelines (one for each platform) and maintain a
separate primary codeline for platform independent-code.
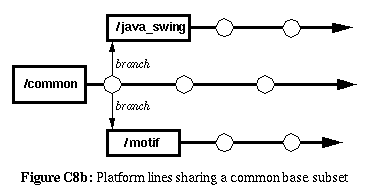
In more complex cases, there may be platform families: subsets of
platforms with common needs and constraints. In these situations, you
may need to create platform-family-lines, in addition to specific
platform-lines and a lone common-platform line.
For example, you might have a program that needs to run on multiple
varieties of Unix (Solaris, AIX, HP-UX, Linux) and Windows (Windows'95
and Windows/NT). The common-platform line will be the primary
development line and contain platform independent files and changes.
Branched off of that will be the platform-family lines (e.g., Unix and
Windows) containing files and changes common to all platforms in the
family. Finally, branching off from the platform-family lines will be
the lone platform lines (e.g., Linux, AIX, Windows'95, etc.) for files
and changes specific to that platform alone.
|
Resulting
Context |
-
Platform-specific files, their revisions and configurations can be
easily selected by using the platform-line (and platform-family line
if present) for a given platform.
-
Once the desired platform lines have been selected in the workspace,
the correct contents and information should be present to properly
build and execute the software for the particular platform-variant.
-
Platform-specific files and changes can easily be identified by
examining the branch to which a file revision belongs.
-
The use and selection of platform lines make only one platform visible
at a time in the developer's workspace. This means less confusion
about which platform a set of files or changes is intended for.
-
You won't be able to build for multiple platforms at once. Building for
multiple platforms simultaneously will require not only a separate build,
but the workspace will first have to be reconfigured for each platform.
This is one of the main reasons why using platform-directories is
preferable if it can be done.
-
Most version control tools let you select specific revisions of files,
but not of directories. They will give you all files in a directory, even
if some of those files aren't needed for a given platform. For tools like
ClearCase that do version control the contents of directories, branching
of directory-contents is more complex than of file-contents, and should not
be taken lightly. This is another reason why platform-directories are
preferable to platform-lines when possible.
|
Related
Patterns |
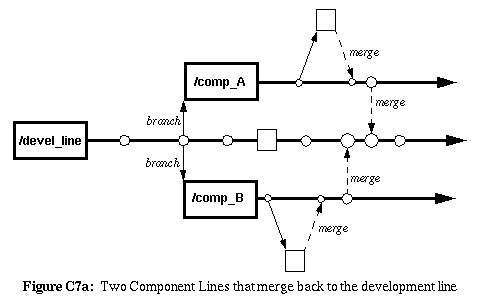
Codelines for components that exist only for a certain platform,
or platform family, can be treated like a Component-Line.
The use of Codeline-ownership is especially important for
platform lines since they rarely converge back to their parent codelines.
The codeline/platform owner will have to be on the lookout for files can
be merged back to a common platform line or family, as well as for file
revisions that need to move from a common platform to a family platform,
and from a family platform to a single platform. The Codeline
Policy used for platform lines will need to make special mention of
when and why to merge to and from platform lines, platform-family lines,
and the common platform line.
|